pyquery爬取维基百科时遇到的蛋疼问题
pyquery爬取维基百科时遇到的蛋疼问题
因为期末作业,需要爬维基百科的关于武器的数据,相关界面如下( https://en.wikipedia.org/wiki/List_of_artillery_by_name ):
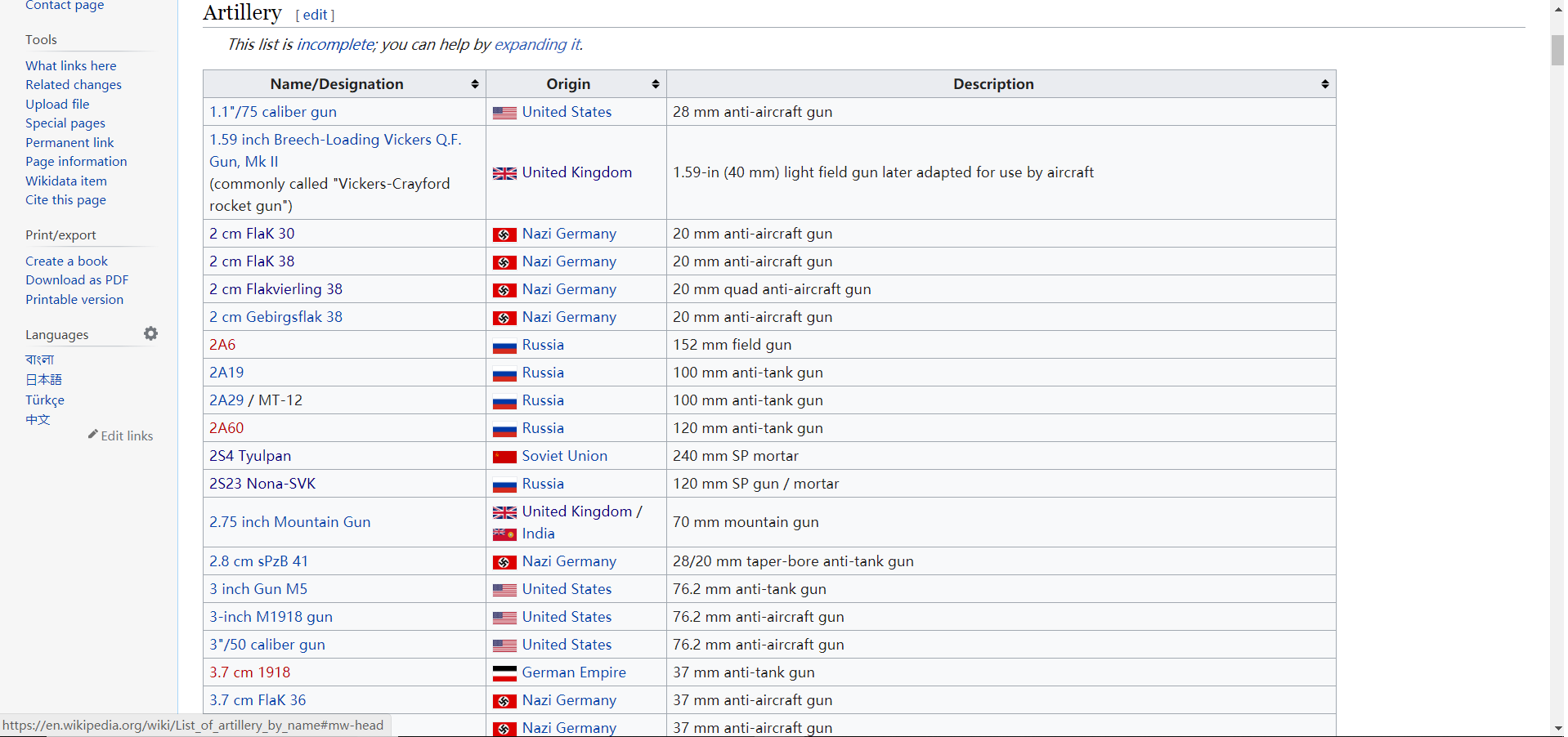
结构如下
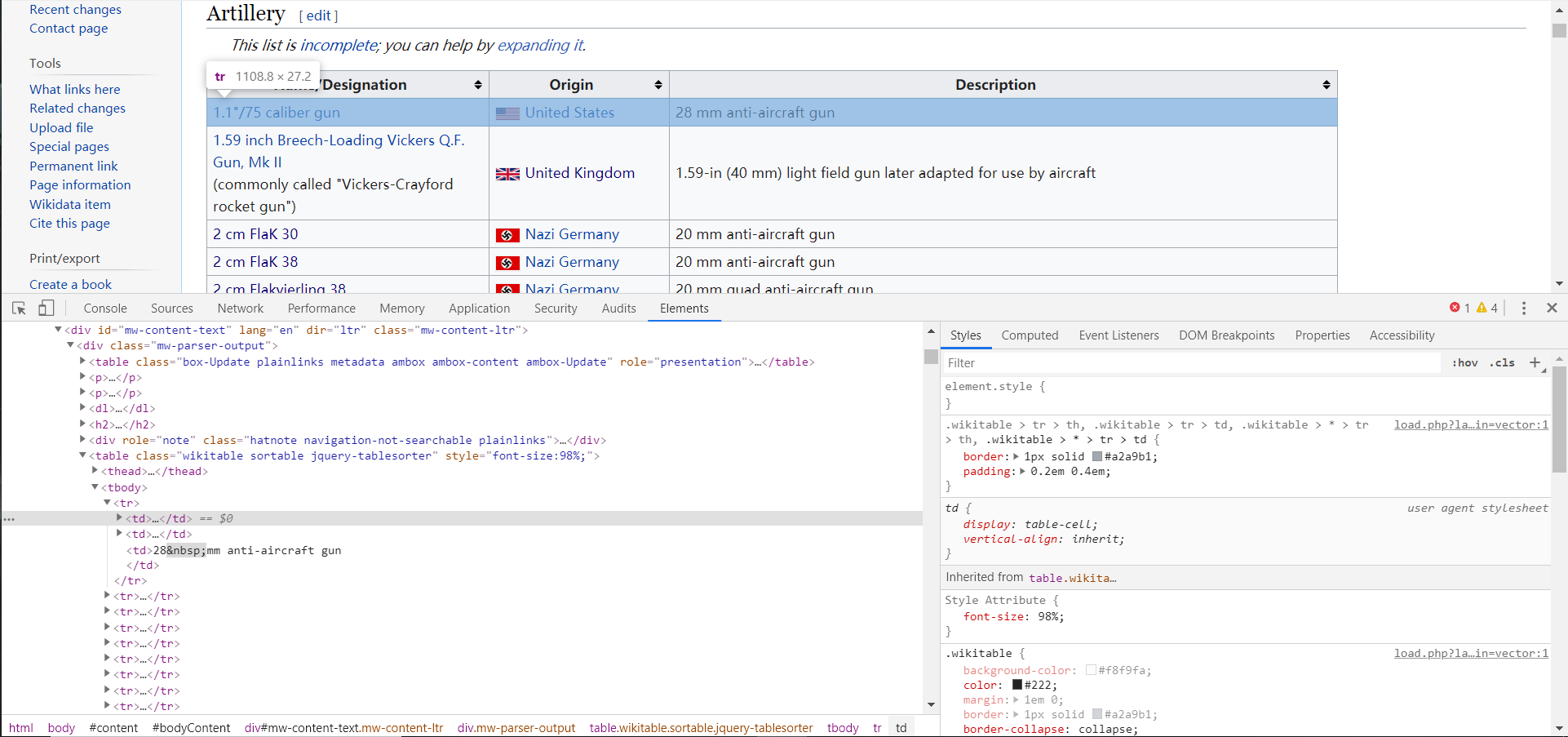
我需要的是每种武器的链接,可以看出,每一条记录存放在表格的每一行,而且一行中可能包含多个链接,所以需要进行筛选。那么用 jQuery 查询的话大概是这样的
$("table tbody tr').find('td:first a')然后在 Chrome 的控制台用运行之后也是可行的,完美的找到了我要的每一个武器的链接地址。但是,当我打开爬虫,用 pyquery 查询时,根本无法筛选掉后面 “美国”、“英国” 等的超链接,也就是说 td:first 这个部分根本没有起到作用。
我试了各种别的方式来获取元素,比如说改成
$("table tbody tr').find('td:eq(0) a')也无法筛选掉后面的元素(但是这边很奇怪的获取了全部三列的元素),甚至怀疑是不是 pyquery 有 bug。
于是上百度查 “pyquery bug”,然后看到很多人说 pyquery 有默认解析的问题,要改成 “html” 解析,我试了一下,无果。
然后又看到有一篇博客提到了和我很像的问题,博文链接 https://www.jianshu.com/p/4a0ff42b7a2c 这位博主获取不到 tbody 里的内容,是因为不支持 tbody 这个标签产生的问题,然而我这里可以获取到,只是获取多了。我还是照着他说的改了一下,发现并不是 table 标签的问题。
然后高潮来了,博主查询表格时用的是
td:nth-child(2)然后我也阴差阳错般地跟着把 td:first 改成了 td:nth-child(0) 结果是什么都没获得,于是我很奇怪,又改成了 td:nth-child(1) ,然后就对了!就对了???
WTF???我把查询代码放到控制台运行了一下和我第一条语句得到的结果一模一样,说明这两条语句都是对的,那为什么到pyquery这边不能用了呢?
我试着获取了一下
td:nth-child(2)
td:nth-child(3)
td:nth-child(4)的数据,4th 的数据是空的(因为表格一行只有三列),其他都是对应的数据,难道说pyquery里面的子元素下标是从1开始的??
于是我改成
td:eq(1)但是,什么都没有获取到,反倒是之前的 eq(0) 获取到了全部三列的元素,真有你的啊 pyquery
那么问题是解决了,但是问题产生的原因呢,我还是不清楚,我的猜测是,pyquery 在获取td标签时,把一整行(tr)的 td 标签的内容,全都放到一个 td 标签下了,并改成了这个td的子元素了,导致了我只能获取td的子元素而获取不到 tr 的第 n 个 td 元素。
为此,我去试着爬了一下别的带有表格的网站,结果也是一样,只能用 nth-child 来获取一行中的第 n 列的元素,神秘。
如果有dalao知道原因,请告诉我,お願い。